Après avoir aspiré nos fichiers et créés les nuages, nous avons utilisé un outil informatique appelé "le Trameur". Cet outil sert à analyser le texte pour déterminer la fréquence d'un mot donné et le contexte dans lequel il est employé. Pour réaliser cette analyse, il est nécessaire de préciser qu'il faut délimiter son texte avant de le soumettre au logiciel. La délimitation se fait à l'aide de cette commande: §. Celle-ci se place avant les balises qui servent à déterminer les paragraphes.
§ བཟང་སྤྱོད་ལྡན་པའི་མི་ཚེ་ཇི་ལྟར་སྐྱེལ་དགོས་སམ། བཟང་སྤྱོད་ལྡན་པའི་མི་ཚེ་ཇི་ལྟར་སྐྱེལ་དགོས་སམ། བཟང་སྤྱོད་ལྡན་པའི་མི་ཚེ་གཞི་རྩར་བཞག་ནས་རང་དོན་གྱི་ཁ་གཏད་དུ་གཞན་དོན་སྒྲུབ་པ། དེ་ནི་བཟང་སྤྱོད་དང་ལྡན་པའི་མི་ཚེ་སྐྱེལ་བའི་སྙིང་པོ་ཡིན། དེས་ན་གང་ཟག་སྒེར་ཞིག་གི་ཐོག་ནས་བཟང་སྤྱོད་ལྡན་པའི་མི་ཚེ་ (ethical life) ང་ཚོ་སོ་སོའི་མི་ཚེ་སྐྱེལ་སྟངས་ཀྱིས་གནད་དོན་དེ་དག་ལ་བསམ་ཞིབ་བྱེད་དགོས། མི་ཁ་ཤས་ཀྱི་མི་ཚེ་སྐྱེལ་སྟངས་ནང་རྒྱས་སྤྲོས་ཆེ་དྲགས་ཀྱི་ཡོད། གལ་ཏེ་མི་ཚང་མར་རྒྱས་སྤྲོས་ཆེན་པོའི་མི་ཚེ་སྐྱེལ་སྟངས་མཉམ་པ་ཞིག་ཡོད་ཚེ་འག འོན་ཀྱང་དེ་ལྟར་མ་བྱུང་བར་དུ་ཆོག་ཤེས་ཆེ་བ་བྱེད་པ་དེ་མི་ཚེ་སྐྱེལ་སྟངས་ལེག ཉམས་མྱོང་བྱུང་བ་བཞིན་མི་ཚེ་སྐྱེལ་སྟངས་ལ་ལེགས་བཅོས་འགའ་ཞིག་དགོས་ཀྱི་འདུག དེས་ན། བཟང་སྤྱོད་ལྡན་པའི་མི་ཚེའི་ཁྱད་ཆོས་འཕར་མ་ཞིག་ནི་དཔེར་ན། བཟང་སྤྱོད་ལྡན་པའི་མི་ཚེ་ནི་འཇིག་རྟེན་ཀུན་ཁྱབ་སེམས་འཁུར་ལས་འོང་གི་ཡོད་པ་ དེ་དག་གིས་བཟང་སྤྱོད་ལྡན་པའི་མི་ཚེ་སྐྱེལ་སྟངས་སྨྲོས་པའི་ང་ཚོའི་བདེ་སྐྱིད སྐབས་དང་གནས་འདྲ་མིན་དང་མི་ཚེ་སྐྱེལ་སྟངས་འདྲ་མིན་བྱུང་བ་ནི་ཁོར་ཡུག་གི་ཁྱ * བཟང་སྤྱོད་ལྡན་པའི་མི་ཚེ་གཞི་རྩར་བཞག་ནས་རང་དོན་གྱི་ཁ་གཏད་དུ་གཞན་དོན་
Par ailleurs les paragraphes traités sont ceux qu'on a obtenus après avoir aspirés les pages. Donc une fois aspirés, on obtient deux onglet sous les tableaux que sont les "fichiers_dumps_globaux" et les "fichiers _contexte_globaux". Mais nous nous sommes intéressés qu'aux fichiers contextes globaux pour faire notre analyse textométrique.
Pour ce qui est du Français nous avons obtenu ce tableau en premier:
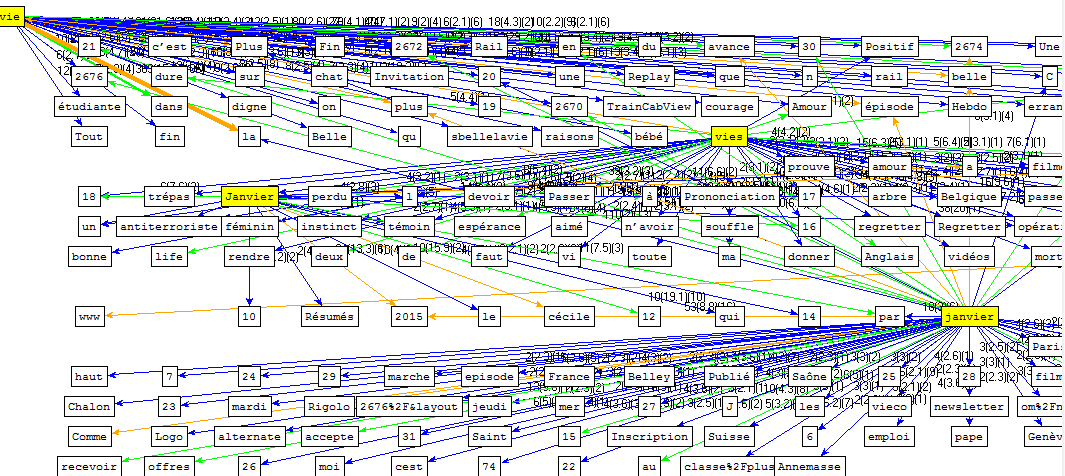
Ce tableau génère tous les co-occurrents du mot la vie car nous avons utilisé l'onglet "cooc". Vous remarquerez la présence d'autres mots que la "vie" comme "janvier", "vies" et "vied".
Ainsi pour ne pas que le trameur nous affiche ces mots dans notre tableau, nous avons écrit le mot en commençant par une majuscule. Voici le résultat obtenu:
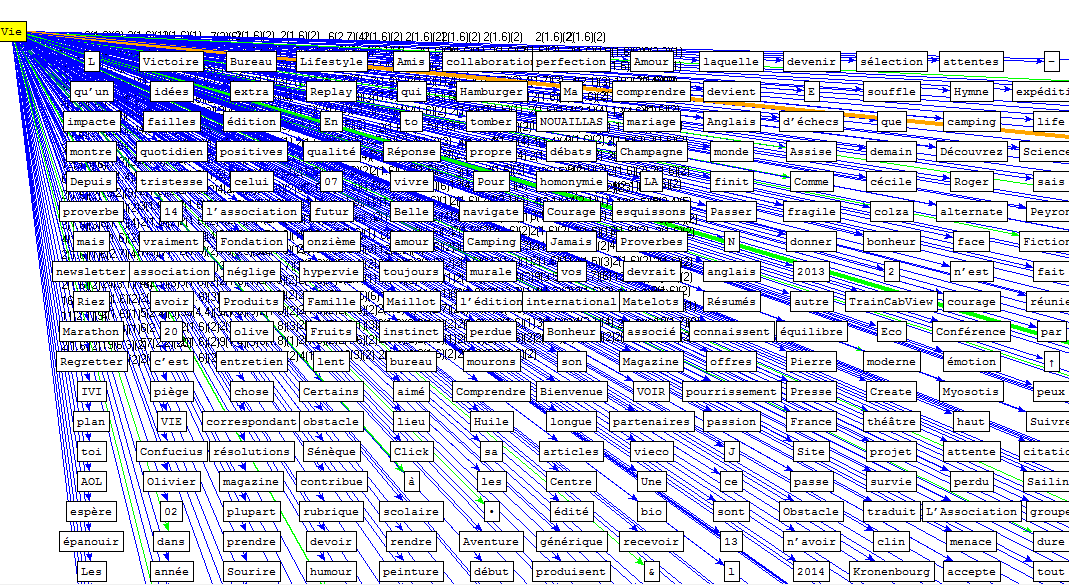
Pour l'anglais nous n'avons pas eu besoin de la majuscule car le résultat n'a affiché que le mot "life"
Il est toutefois important de préciser qu'il y'a un bon nombre de choses à faire sur trameur avant de pouvoir arriver à ces résultats.
Devant son logiciel Trameur, il faut toujours penser à cliquer sur l'onglet "Paramètres" pour choisir l'encodage approprié et la langue aussi (si nécessaire).C'est le sous-onglet "importer une nouvelle base" qui se trouve dans l'onglet "Cadre" qui permettra d'importer son fichier.

Pour avoir accès aux différentes formes du mot, il faut l'onglet "forme-lemme".
La fonction "Concordance" affiche les concordances du mot dans chaque paragraphe.

Le "Tri concordance" joue le même rôle en assemblant les résultats dans un tableau tout en précisant le paragraphe dans lequel le mot est employé.

Voici les tableaux des coocurents:
en Anglais "life"

en Thaï "ชีวิต"

en tibétain "མི་ཚེ"
Certainement vous vous demanderez il n’y a pas tableau d’occurrences pour le tibétain. En effet, dès que nous importons le fichier « tibétain », le trameur se plante. Nous nous sommes dit que c’était un souci d’encodage. Nous essayons l’utf-8 mais le trameur n’accepte toujours pas de l’ouvrir. Nous avons même réécrit tout le fichier afin de nous assurer que nous avons mis tous les délimiteurs mais pas de résultat. On n’a pas pu détecter où se trouvait l’erreur.
en wolof "dund"

En conclusion le Trameur est un outil très utile pour faire une analyse linguistique dans la mesure où elle nous permet d’accéder à toutes les fonctionnalités linguistiques que sont par exemple la concordance du mot. Il détermine aussi les paragraphes dans lesquels le mot est employé et le nombre d’occurrences dans un ou plusieurs paragraphes donnés.